November 8, 2022 in Thought leadership
Origin stories: Data culture
Take a deep dive into data’s origin story as we explore etymology, historical context, and the importance of a data-driven culture.

We’re living in a state of perpetual connection. And as consumers embrace more innovative technologies and continue to set the bar higher for companies to deliver heightened personalization, meeting our own expectations depends on data. Yet we tend to fear the very thing that drives the experiences we’ve come to rely on.
Big data, consumer data, personal data — various iterations of these terms are often a source of tension as we debate the balance between privacy and meeting elevated expectations for bespoke service. But what do we actually know about data? Where did it come from? Where is it going? How will we be affected?
Even for those of us who aren’t digital natives, it’s almost hard to imagine life without the internet or Big Data. Yet, unlike the internet, data analysis and collection have long existed, relative to available technologies of the time.
This is data’s origin story — an exploration of its etymology and how a verb, dare, outgrew its Latin roots (“to give”) and became something we’re reluctant to part with, despite the opportunities it can present.
“But what do we actually know about data? Where did it come from? Where is it going? How will we be affected?”
History of data
The word “data” dates back to the 17th century and is the plural form of the Latin verb datum, which was derived from the verb dare. In 1640, when data’s first English usage appeared, it was defined as “a fact given or granted.”
While the concept of data is inextricably linked to information technology in the modern mind, humans have been collecting data for millennia. Tally sticks, like the Ishango Bone, were used to keep track of trading activity or supplies as early as 19,000 BCE.
But as society evolved and our needs became more complex, data recording and storage needed to be more sophisticated. Two of the earliest foundational steps to the modern conception of data came in the 1600s and 1800s, respectively.
John Graunt is credited with being the first person to use statistical data analysis when, in 1662, he published a collection of public health records as the bubonic plague was ravaging Europe. Early data processing began in 1884 with Herman Hollerith’s punch card tabulating machine. Hollerith’s device made it possible to process and analyze large amounts of data and it was applied to the 1890 U.S. census, with automation reducing processing times from 10 years to three months.
From that point on, the advent of more advanced data processing machines and ways to store data marked the beginning of a new era — and accelerated technological advancements began changing the data landscape across all industries.
Data as we know it
After data processing problems were partially solved in the 1800s, the emphasis shifted to recording and storing it. Fritz Pfleumer developed magnetic tape technology in 1928, and the hard disk drives, floppy disks, and flash storage devices that followed all paved the way for today’s distributed storage models, like cloud storage.
Although the concept for cloud-based storage has been around since the 1960s, it wasn’t until the late 1990s that modern cloud computing infrastructure became concretely possible as the Internet evolved, and the concept of virtualization along with it.
Currently, two-and-a-half quintillion bytes of data are created daily. Legacy data technology just wasn’t built to handle modern daily data needs or the predictive analytics that are required for companies to remain competitive in a data-driven culture.

Data and finance: Past and present
Although there are myriad benefits to a data-driven culture, its full acceptance hinges on a shift in consumer mindsets – particularly when it comes to finance. Generally speaking, consumers have more or less accepted sharing their data in exchange for the convenience that personalized, digital experiences can offer them.
Yet due to the historically sensitive nature of personal finance and a slower adoption of technology in the financial services industry, when it comes to sharing personal financial data, consumers tend to hold their financial institutions to a higher standard.
The truth is, banks have always had access to consumer data, and they have used that information to make more informed decisions. The practice was given a name in the 1800s, when Richard Millar Devens coined the term “Business Intelligence (BI)” to describe how Sir Henry Furnese, a banker, was able to use data he had collected about his customers to improve the timeliness and quality of decision-making processes — and yes, to gain a competitive edge.
Modern technology, like cloud infrastructure and predictive analytics, have made it possible for financial institutions to leverage existing consumer data at a scale unimaginable to Furnese or Devens. Today’s BI practices enable large-scale conversions of big data into actionable insights that can be used to reduce risk, increase security, improve internal operations, and offer more personalized services.
As a result, financial services are becoming increasingly customer-centric – and it’s just the beginning.
Data and the future of finance
With the proliferation of data and technological advancements, the way the financial services industry operates and competes has already been impacted. If financial institutions can successfully build trust by communicating and demonstrating strong data privacy and security practices, consumers will be able to reap the benefits of more personalized, secure, and proactive financial services.
The volume of available data, decades of financial expertise, and carefully earned client trust have given financial services institutions a unique opportunity in the current digital landscape. Implementing innovative business models and strategies allows them to create a new wave of offerings that set consumers up for financial success now – and can only lead to continued success regardless of what’s on the horizon.

Looking to find more origin stories?
Find out what we're up to!
Subscribe to get Blend news, customer stories, events, and industry insights.
How Lenders Can Reach More Bilingual Borrowers Without Adding Friction
Bilingual borrowers are a growing market. See how clarity, not just translation, builds confidence and keeps loans moving.
Read the article about How Lenders Can Reach More Bilingual Borrowers Without Adding Friction
Autopilot Update: A Pre-Underwriting Summary That Shows Its Work, and Sharper Income and Asset Judgment
Every figure, every source. See how Autopilot's latest update makes pre-underwriting faster to act on.
Read the article about Autopilot Update: A Pre-Underwriting Summary That Shows Its Work, and Sharper Income and Asset Judgment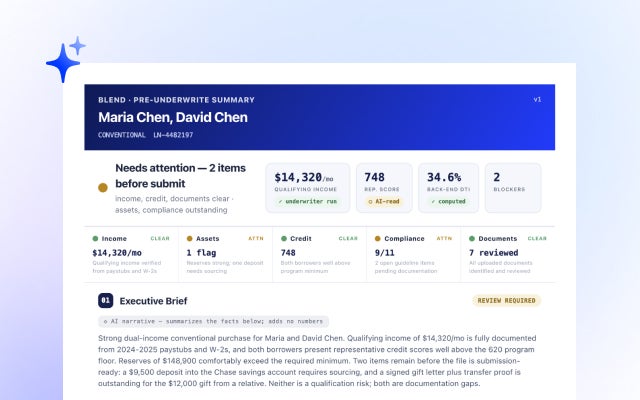
Competing in a Flat $2.2 Trillion Market by Fixing Cost per Loan
The mortgage market is projected to reach $2.2 trillion in 2026, but flat isn't the same as easy. With per-loan costs exceeding $12,500, discover why cost per loan is the…
Read the article about Competing in a Flat $2.2 Trillion Market by Fixing Cost per Loan